
For a long time the story of AI infrastructure was straightforward: more GPUs, faster GPUs, bigger GPU clusters. That story has shifted somewhat. As agentic AI reshapes how compute is consumed, the CPU has returned as a first-order item in datacenter design (see the Lazurus-like recovery of Intel). The NVIDIA Vera CPU is a fully custom processor built specifically for the demands of agentic workloads and reinforcement learning at AI factory scale.
As a quick reminder, NVIDIA's AI platforms pair a custom CPU and GPU that are co-designed as a single system. The current generation is Grace (CPU) Blackwell (GPU) today and Vera Rubin next. Unlike traditional architectures where CPUs and GPUs are developed independently and connected after the fact, NVIDIA engineers the compute, memory, networking, and software stack together to maximize performance and efficiency for AI workloads.
Why CPUs Matter Again: The Agentic AI Shift
For most of the deep learning era, the datacenter CPU was an afterthought, the node that booted the server, loaded the data, and handed off to the GPU. Training-centric workloads ran comfortably at CPU-to-GPU ratios of 1:8. That assumption began to break in 2025 with the rise of agentic AI.
Unlike a single-pass inference call, an agentic workflow is a dynamic graph of operations: Python sandbox execution, vector database retrieval, API tool calls, reinforcement learning rollout evaluations, each of which demands CPU cycles, not GPU cycles. The more capable the agent, the more steps it takes, and the more heavily it taxes the host processor.
This is turning out to be a secular trend in AI infrastructure, AMD has also observed that agentic architectures are trending toward a 1:1 CPU-to-GPU ratio. Arm estimated that while traditional AI datacenters require roughly 30 million CPU cores per gigawatt, the agentic era would demand 120 million, a fourfold increase.
By early 2026, CPU supply had tightened to the point where Intel and AMD were raising server CPU prices. Counterpoint Research described an "agentic AI-driven CPU renaissance" reshaping competitive dynamics industry-wide.
💡Why it matters: When agents execute tool calls, compile code, or evaluate RL trajectories, those operations land on the CPU. If the CPU cannot sustain throughput, GPUs stall waiting for work, turning the most expensive assets in the rack into idle hardware.
It is against this backdrop that NVIDIA has introduced the Vera CPU.
Vera CPU Specs at a Glance
Vera CPU Architecture: The Olympus Core in Detail
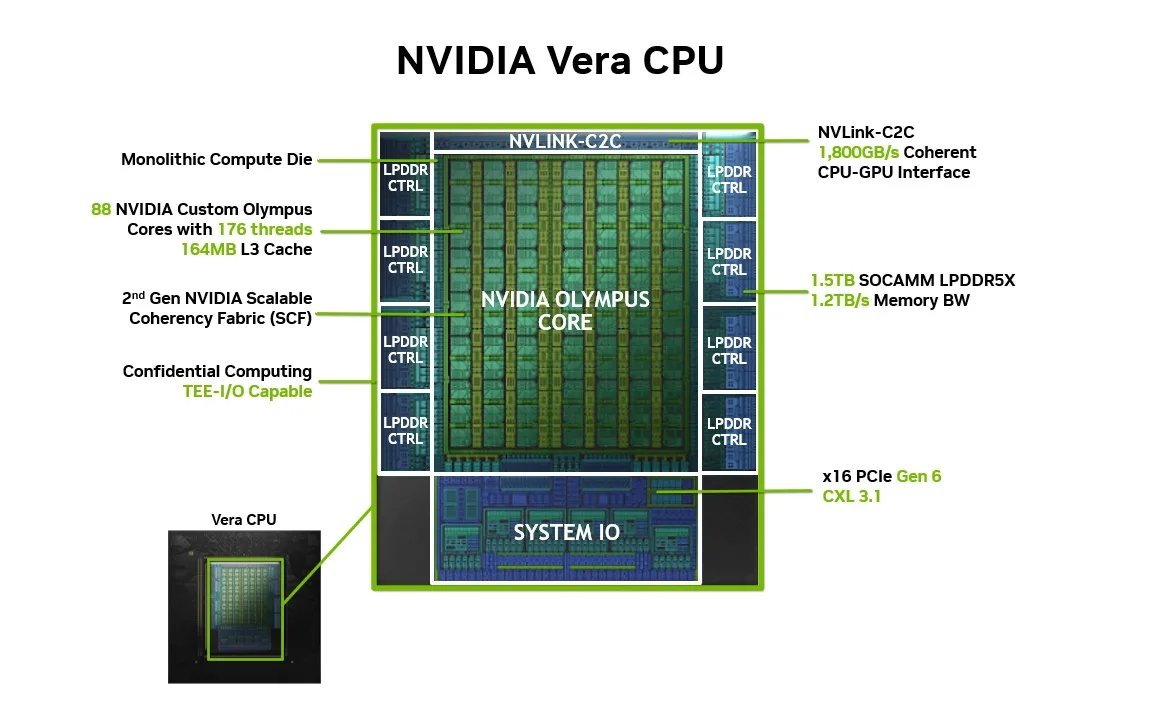
Each Vera CPU consists of 88 custom Olympus cores. The Olympus core makes several architectural choices that distinguish it from both Arm IP and current x86 designs.
Monolithic Die: All 88 cores sit on a single reticle-sized 3 nm compute die, with memory and I/O disaggregated into adjacent chiplets via CoWoS-R packaging. The monolithic compute topology preserves uniform memory access latency across all cores — a deliberate tradeoff against the yield complexity of a large die, based on the judgment that latency unpredictability from chiplet boundaries would be more damaging than yield costs for Vera's target workloads.
💡How it helps: For agentic AI's unpredictable access patterns, the latency uniformity of a single coherent die is worth the additional manufacturing expense for NVIDIA. Operators do not need to NUMA-tune their software stack to get predictable behavior
Configurable TDP: Vera's 250–450 W TDP range is operator-configurable. At lower settings it fits standard air-cooled racks; at higher settings with liquid cooling, all 88 cores can sustain full bandwidth under continuous AI factory load.
💡How it helps: This range gives cloud operators flexibility to serve diverse workloads from a single hardware SKU.
The Return of Custom CPU Design: NVIDIA's last custom CPU core was Carmel in Tegra Xavier, descending from the Project Denver architecture. The eight-year gap reflects a strategic choice to rely on Arm IP while the GPU business scaled.
💡How it helps: Rebuilding the custom CPU team for Olympus signals that agentic AI workloads now require differentiation that commodity cores cannot deliver, a thesis the benchmark results support.
Native FP8 on CPU: SVE2 FP8 support on Olympus enables lightweight model scoring and quantized inference steps to run entirely in the CPU pipeline without GPU dispatch.
💡How it helps: As FP8 becomes a standard weight and activation format for deployed models, this capability reduces GPU context-switching overhead for mixed-precision workloads and opens CPU-native inference for smaller models.
Front End Width: Olympus uses a 10-wide instruction fetch and decode frontend. AMD's Zen 5 is 8-wide; Intel's Granite Rapids and Arm's Neoverse V2 are both 6-wide.
💡How it helps: A wider front-end fills the out-of-order execution engine even when code paths are irregular. Agentic code (runtime interpreters, dynamic dispatch, graph traversal) is notoriously hard to parallelize at the instruction level. The 10-wide decoder keeps the pipeline busy even when the scheduler has less to work with.
Neural Branch Prediction: Olympus uses a neural branch predictor capable of evaluating two taken branches per cycle with zero penalty. Unlike conventional predictors, a neural predictor captures longer-range correlations across complex, history-dependent code paths which can directly reduce stalls in the PyTorch runtimes, JavaScript engines, and scripting interpreters that underlie most agentic software stacks.
💡How it helps: To complement this, Olympus includes a deep out-of-order engine with large reorder and scheduling buffers that maintain forward progress as workload patterns shift.
Doubled Cache per core: Each core carries 2 MB of private L2 cache, double Grace's allocation and the unified L3 reaches 162–164 MB in total.
💡How it helps: For agentic workloads making repeated passes over KV-cache representations, context buffers, and tool-call payloads, a larger per-core cache reduces memory round-trips and helps sustain IPC under irregular access patterns.
IPC Uplift: NVIDIA claims up to 50% higher Instruction per cycle (IPC) over Grace which is one of the larger single-generation jumps in recent datacenter CPU history.
💡 How it helps: AI systems can execute significantly more complex reasoning chains, tool calls, and multi-step orchestration loops per clock cycle, accelerating the "think-act-observe" cadence
Spatial Multithreading: Physical Partitioning, Not Time-Slicing
Vera introduces what NVIDIA calls Spatial Multithreading (SMT), a concurrency model that differs meaningfully from the SMT in Intel and AMD processors. Conventional SMT time-slices a core's shared resources between two threads, creating contention that can cause threads to interfere with each other's branch predictor and cache state.
Olympus instead physically partitions the core's resources between two threads. Execution units, register files, and scheduling buffers are divided so each thread has dedicated access to its allocated portion. When one thread's execution elements are idle, the other can fill them, increasing throughput without the unpredictable contention of shared-resource SMT.
The result is 176 threads from 88 physical cores, but with the per-thread isolation that multi-tenant AI factory deployments require. For reinforcement learning loops that must complete evaluations under timing constraints, predictable per-thread latency is a reliability property and not just a performance requirement.
💡Why it matters: In a multi-tenant AI factory running hundreds of agent environments on shared infrastructure, one tenant's workload can interfere with the branch predictor or cache state for a co-resident environment under conventional SMT, resulting in unpredictable latency spikes. Spatial Multithreading eliminates this contention, making Vera's per-thread latency guarantees reliable rather than probabilistic
Memory Subsystem: 1.2 TB/s at a Fraction of the Power
Vera's memory subsystem is built around LPDDR5X rather than the DDR5 that dominates x86 server platforms. The difference is material at both ends of the spec sheet.
The physical packaging reflects a deliberate architectural tradeoff. Eight 128-bit SOCAMM modules support up to 1.5 TB of total system memory, accommodating large KV-cache management, in-memory analytics, and the simultaneous state of thousands of RL environments.
The Scalable Coherency Fabric (SCF): Consistent Bandwidth at Scale
The second-generation NVIDIA Scalable Coherency Fabric is the on-die interconnect that connects all 88 Olympus cores to a shared L3 cache and memory subsystem on a single monolithic compute die. By avoiding chiplet boundaries in the compute fabric, unlike AMD's EPYC, which aggregates multiple compute chiplets with inherent inter-die latency variation, the SCF gives every core a uniform, predictable path to memory and to every other core.
The SCF delivers 3.4 TB/s of bisection bandwidth, allowing 88 cores to access a shared L3 simultaneously without bandwidth collapse. Core-to-core data movement is 50% faster than CPUs that fragment compute across dies, a concrete advantage for reinforcement learning loops that synchronize policy updates across many concurrent environments, and for agentic orchestration where sub-agents pass partial results upstream. The monolithic coherency architecture also supports full confidential computing, providing hardware-enforced memory and execution isolation that enterprise and sovereign AI deployments increasingly require.
From Grace to Vera: Why a Custom Core Was Necessary
NVIDIA's prior CPU, Grace, used Arm's Neoverse V2 cores on a 6×7 mesh with 72 active cores and up to 500 GB/s of LPDDR5X memory bandwidth. For GPU-centric HPC and large-model inference, Grace was a capable host processor. For agentic AI, it was not designed for the job.
💡 Why custom IP: Agentic workloads are branch-heavy and control-flow intensive. An agent executing a tool-call chain stalls when cores mispredict branches. A reinforcement learning loop needs consistent latency across every core, not just aggregate throughput. These are demands that off-the-shelf Arm IP was not specifically tuned to address.
NVIDIA's conclusion was that the next generation required a fully custom core, the first custom data center CPU in the company's history, and its first custom CPU architecture since the Carmel cores in Tegra Xavier nearly eight years ago. The result is Olympus: a microarchitecture built for the control-plane characteristics of agentic AI, with a wider front end, more capable branch prediction, deeper out-of-order scheduling, and memory access patterns optimized for the pointer-chasing, irregular workloads that agent runtimes produce.
How does the Vera CPU compare with Grace CPU
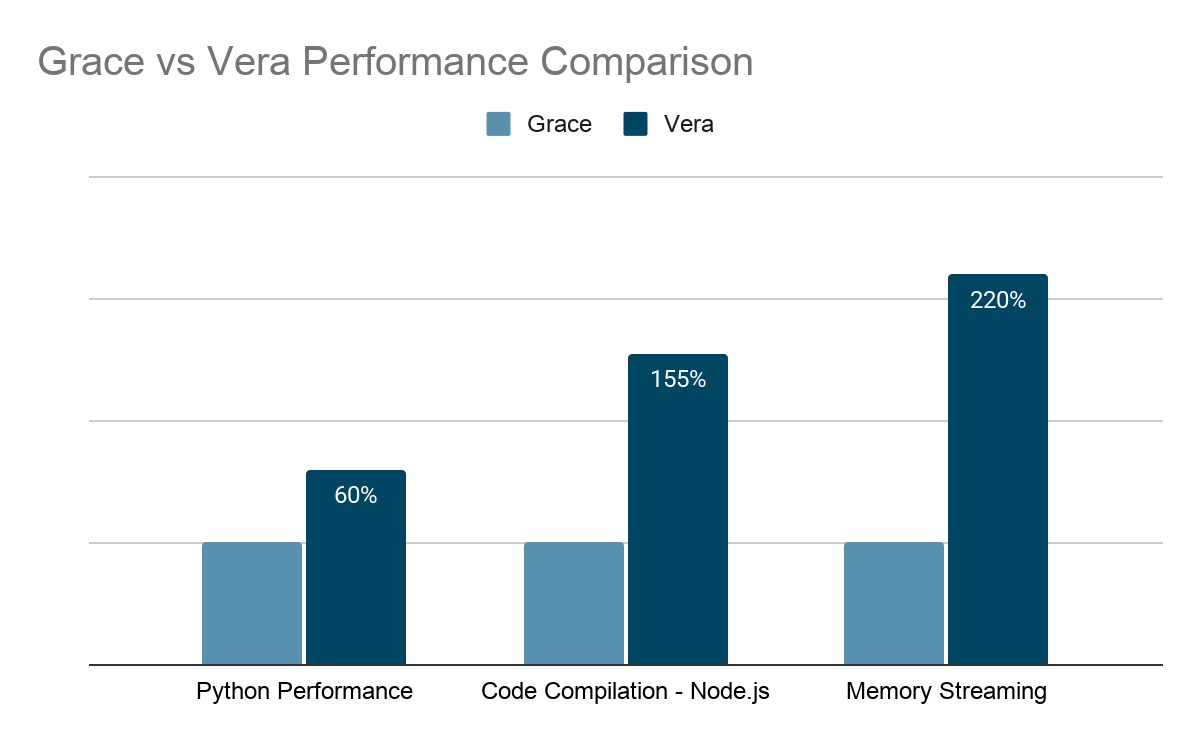
The transition from Grace to Vera represents a substantial generational leap, characterized by a 50% increase in IPC and more than double the memory bandwidth at 1.2 TB/s. While Grace was highly capable for general HPC, Vera’s 10-wide decoding architecture and expanded cache hierarchy provide the specific throughput needed to eliminate bottlenecks in control-flow-intensive agentic workloads. The performance impact from these architectural enhancements are very evident with 60% improvement in Python operations, 155% faster code compilation, and 220% better memory streaming.
*Results from PyPerformance 1.12 - Django Template, Node.js 21 Total Compilation Time, Stream 2013-01-17: Triad
NVIDIA Vera CPU vs Intel Xeon and AMD Epyc: Benchmark Results
The first independent Vera CPU vs Intel and Vera CPU vs AMD comparison data came from Phoronix, which tested Vera against a 128-core x86 competitor representing the latest generations of Intel Xeon Granite Rapids and AMD EPYC Turin.
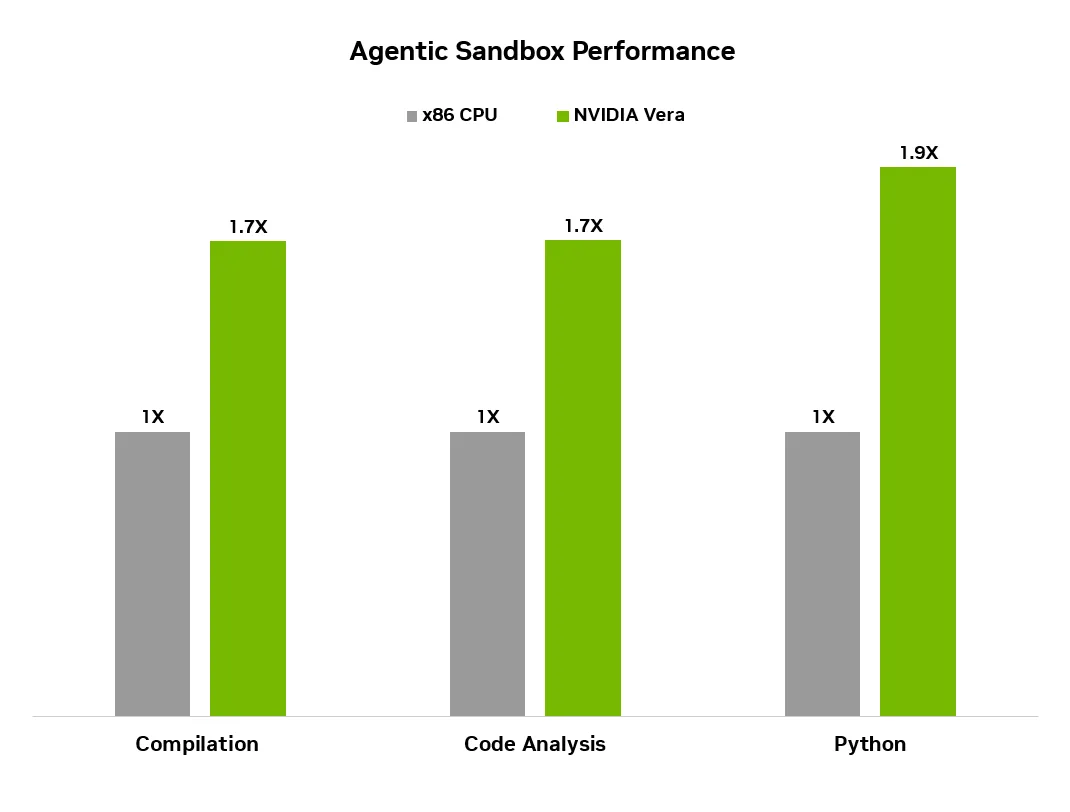
The NVIDIA Vera CPU delivered a 1.5× overall performance advantage. In practical developer workloads, a single-socket Vera CPU compiled the default Linux kernel in 20 seconds , the fastest result Phoronix had recorded in that test and delivered 2× faster per-core kernel compilation than the 128-core competitor.
For agentic sandbox performance, the most operationally relevant measure, NVIDIA's benchmarks show more than 1.8× higher throughput on agentic workloads under full load compared to competitive platforms and up to 50% faster sandbox performance compared to the prior generation.
Redpanda's independent benchmark across five competing systems found Vera delivering the lowest streaming latencies in every tested configuration: up to 5.5× lower than AMD EPYC Turin and more than 2.5× lower than Intel Xeon 6 Granite Rapids, with up to 73% higher throughput than EPYC Turin. TechPowerUp confirmed the pattern: the Vera CPU beat both latest-generation Intel Xeon and AMD EPYC in the data center workloads where it is positioned .
The practical implication for infrastructure operators is that a CPU delivering 2× performance per watt changes the economics of the entire CPU layer: fewer racks to support a given GPU cluster, lower power and cooling overhead, and higher sustained GPU utilization.
The CPU Rack: 256 Processors, 400 TB, 22,500 Environments
The NVIDIA Vera CPU is available as a standalone processor and as part of the Vera CPU Rack — a purpose-built deployment unit built on the NVIDIA MGX platform. The Rack integrates up to 256 Vera CPUs and 64 BlueField-4 DPUs in a single liquid-cooled footprint, delivering more than 22,500 CPU cores, 400 TB of addressable memory, and the capacity to run over 22,500 concurrent reinforcement learning environments. The 400 TB memory capacity is significant: each RL environment must maintain its own state, context, and trajectory history, and keeping thousands of environments in memory (rather than thrashing to storage), directly determines training throughput.

Vera is available in single-socket and dual-socket configurations with both air-cooled and liquid-cooled options, supporting deployments from standard enterprise data centers to high-density agentic AI infrastructure.
Vera in the Rubin Platform

While the Vera CPU is available standalone, its primary role within NVIDIA's roadmap is as the host CPU in the Vera Rubin NVL72 platform. In that configuration, Vera connects to Rubin GPUs via NVLink Chip-to-Chip (C2C) at 1.8 TB/s, double the bandwidth of the Grace Hopper generation. This high-bandwidth connection allows Vera to act as the data movement and orchestration engine for the GPU cluster: managing KV-cache state, loading context windows, and coordinating inference pipelines with minimal transfer overhead.
At scale, GPU utilization is gated not just by compute density but by how efficiently data and control flow through the entire system. Vera is designed explicitly for this role. NVIDIA extended Grace's foundation with higher core density, significantly greater memory bandwidth, an upgraded SCF, and confidential computing, producing a processor capable of sustaining GPU throughput rather than bottlenecking it.
What This Means for AI Infrastructure Planning
The CPU:GPU ratio is no longer a fixed parameter inherited from training-era assumptions. Agentic deployments require active sizing based on agent density, tool-call rate, and RL throughput, and getting that ratio wrong means underutilized GPUs and wasted capex. CPU supply is tightening and procurement lead times are lengthening; infrastructure teams that plan on prior-era ratios will find themselves constrained.
Vera's efficiency profile directly affects those economics. At 1.2 TB/s of memory bandwidth in under 30 W of memory power (vs DDR5's 600 GB/s at over 100 W), Vera shifts the power and cooling cost curve of the CPU layer significantly. At AI factory scale, those operational savings compound over the lifecycle of the deployment and determine whether the infrastructure is economically sustainable, not just technically capable.
Is the NVIDIA Vera CPU right for your workload?
The Vera CPU is designed for workloads where CPU throughput, memory bandwidth, and multi-tenant isolation are the limiting factors. It is well suited for:
- Reinforcement learning post-training, where large numbers of CPU sandboxes must evaluate model outputs quickly to keep pace with GPU token generation
- Agentic AI inference, where agents execute tool calls, run code, and query data stores in multi-step loops that are CPU-bound
- Real-time analytics and ETL pipelines that require sustained memory bandwidth across many concurrent cores
- HPC workloads that benefit from high per-core bandwidth and a large unified cache hierarchy
For organizations running conventional x86 CPUs alongside GPU clusters today and scaling toward agentic or RL-heavy workloads, the practical question is whether the CPU layer will become the bottleneck as agent density grows. The Vera CPU's performance advantage and power savings offer a substantially different operating point than current x86 infrastructure. At Radiant, we support GPU and CPU infrastructure across NVIDIA's product lines. If you're evaluating the Vera CPU for your AI factory deployment, get in touch with our team.
This post is part of Radiant's ongoing coverage of NVIDIA's AI infrastructure roadmap. For a deeper look at how the Vera CPU fits within the Vera Rubin platform and what it means for AI factory design, explore our related posts on the Vera Rubin architecture and NVIDIA's five-layer AI cake.


